
Annotation enables us to transfer our knowledge or meta-knowledge of sources such as texts, images, videos, etc. to a computer or an algorithm. Furthermore, experts can convey detailed descriptions of a source to novices or the general public. In this digital history reflection, I focus on Linguistic annotation.
What is annotation?
An annotation adds a meta-layer to a source in order to identify a meta-concept of the text in a computer-readable mark-up. Linguistic annotation is often described as a tool to bridge the gap between linguistics and computational linguistics. Annotation provides the basis for computational linguistics and machine-learning algorithms used in digital humanities research working on textual sources. Algorithms such as Named Entity Recognition (NER), network analysis, text classification or sentiment analysis often rely on annotation.
The objective of an annotation study is three-fold:
- Devising guidelines with clear explanation and examples to describe the application to a general public, specifically for non-expert annotators.
- Creating annotated datasets which can be used as a reference or resource for the novice in the field.
- Providing input to supervised machine learning algorithms. The algorithms use this input data to learn patterns and can afterwards identify these patterns on unseen items.
Linguistic Annotation levels
Linguistic annotation applications may vary from simple annotation tasks such as Part of Speech (POS) tagging and chunking, to more complicated tasks such as Named Entity Recognition (NER), metaphor, irony and sarcasm detection. The natural language processing pyramid below shows the different stages at which natural language is perceived and analysed.
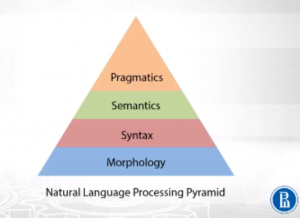
The first layer of natural language analysis is Morphology. Morphological annotation consists of annotation of lemmas, inflections, verb tenses, etc. The VedaWeb project at the department of digital humanities at University of Cologne is an annotation study of Rigveda, one of the oldest religious collections in old Sanskrit. VedaWeb enables historians to thoroughly study this ancient source and its translation on the morphological level.

The second layer of NLP is the level of syntax. At this level, the syntactic structure of the sentence is annotated. Part of Speech tagging and dependency trees are examples of syntactic annotation. NEGRA is a corpus of German newspapers annotated with syntactic structures.
A level higher than syntax is Semantics. The semantic annotation layer involves annotation tasks such as Named Entity Recognition, Event detection, relation extraction, etc. Histograph is a very interesting project which visualises multimedia collections with graph-based visualizations. Histograph is able to automatically detect named entities using crowdsourced annotations and knowledge bases. It helps the users track the use of a certain named entity in different sources on a timeline.
On the Pragmatics level we reach the highly subjective tasks such as sentiment analysis, co-reference resolution and argument structure annotation. Argument mining is my area of research. I have also worked on the annotation of a dataset with arguments. Arguments consist of claims and premises, and the relations between them which can be supportive or attacking. I published a paper called: “Annotation of Argument Components in Political Debates Data” on component annotation task at the Annotation in Digital Humanities workshop in 2018.1

Impresso is a collaborative project between the Centre for Contemporary and Digital History (C²DH) at the University of Luxembourg, the Digital Humanities Laboratory (DHLAB) of the Ecole Polytechnique Federale de Lausanne, and the Institute of Computational Linguistics Zurich University. Impresso incorporates all levels of linguistic annotation on a corpus consisting of 200 years of historical newspapers.
[masterslider id=”9″]
Reproducibility and Inter-annotator agreement
In order to train a supervised machine learning algorithm for natural language processing tasks, one needs to ensure that the defined task or dataset is reproducible. An annotator may decide on labels which other annotators do not agree upon. The higher the annotator agreement, the more well-defined the task is and vice versa.
An algorithm might be unable to find general patterns in a dataset which is only annotated by one annotator. It will be trained on a one-person annotated dataset, hence it will reflect the patterns found based on the mindset of the annotator. The result deteriorates with increasing subjectivity of the annotation concept. Thus, we need to make sure that the annotated dataset can be reproduced. In other words, the task defines the dataset, not the annotator. This problem is addressed by evaluating the annotated dataset with at least two annotators (inter-annotator agreement). Once the dataset is annotated by several annotators, a measure needs to be computed on the mutually annotated parts of the dataset. This measure is called the inter-annotator (or inter-coder) agreement. The mutually annotated section should not be in anyway peculiar so that the agreement measure represents the quality of the entire dataset.
- Observed agreement: the percentage of the items annotated with the same label by different annotators.
- Chance Corrected agreement: This metric evaluates the agreement on labels for items in dataset. However, it considers the probability that the annotators annotate one item with the same label by chance. The chance agreement is extracted from the observed agreement. Figure 1 shows how Kappa coefficient (a chance corrected measurement value) can be interpreted for assessing the quality of annotated data, For more detailed methods on computing IAA please refer to the very detailed survey of Artstein and Poesio.2

Annotation platforms
With the use of machine learning and especially deep-learning rising every day for most Natural Language Processing (NLP) applications, the need for annotated datasets is also rising. One way of annotating huge datasets is to use crowd sourcing. In crowd sourcing the raw dataset and clear and concise guidelines are made available on the web (or other public access platforms) so that volunteers can participate in the annotation process. Amazon’s mechanical Turk provides such a platform for both the dataset providers who want their data annotated and the workers who are willing to spend time annotating these datasets to earn some money.
However, there are a few problems with crowd-sourcing. Firstly, it is costly for the party who needs the annotated dataset, especially if the dataset is big. Secondly, annotation may become tedious after a while, which may affect the annotator’s performance. Thirdly, some tasks may be difficult to explain in words to the annotators.
In order to overcome each of these problems to some extent an interesting solution has been suggested by experts: gaming! Games with a Purpose (GWAP) are used to exploit the time people spend on entertainment to lead to a purpose, an annotation purpose. Instead of paying annotators, these platforms provide and award them with free entertainment which addresses the cost problem. Secondly, gamification may prevent the annotation task becoming tedious. Often it is also easier to explain a game, instead of reading straightforward guidelines for an annotation task. 3
Platforms for linguistic annotations which use GWAP are WordRobe.org, and Phrase detectives. Wordrobe4 provides several games for applications such as Word-Sense disambiguation, Co-reference Resolution, NER and POS annotations. This game is a multiple choice game. Users can also play against other players which makes the game more challenging, competitive and interesting. In order to evaluate the annotations, two metrics are considered. On the one hand, the agreement of different players on the same choice. On the other hand, the bet the player puts on an answer to a question. The higher the bet, the more confident the players are of their answer. Phrase detectives target co-reference resolution which provides an interesting platform to identify references for pronouns.
[masterslider id=”10″]
Annotation helps us explain simple and more complicated concepts in linguistics to humans or machines. Nowadays annotated textual data is sought after by the Natural Language Processing community for training machine learning algorithms. This increases the need for researchers to focus on annotation studies and the creation of high-quality annotated corpora.
- Haddadan, Shohreh, Elena Cabrio, and Serena Villata, “Annotation of Argument Components in Political Debates Data.” In Proceedings of the Workshop on Annotation in Digital Humanities, edited by Sandra Kübler and Heike Zinsmeister. CEUR Workshop Proceedings, 2018. url: http://ceur-ws.org/Vol-2155/haddadan.pdf.
- Artstein, Ron, and Massimo Poesio. “Inter-coder agreement for computational linguistics.” Computational Linguistics34.4 (2008): 555-596. https://www.mitpressjournals.org/doi/abs/10.1162/coli.07-034-R2.
- Jurgens, David, and Roberto Navigli. “It’s all fun and games until someone annotates: Video games with a purpose for linguistic annotation.” Transactions of the Association for Computational Linguistics2 (2014): 449-464. https://www.mitpressjournals.org/doi/abs/10.1162/tacl_a_00195
- Venhuizen, Noortje, et al. “Gamification for word sense labeling.” Proceedings of the 10th International Conference on Computational Semantics (IWCS 2013). 2013.