
From 16 to 17 November 2017 we had a DTU skills training on Database Structures, organised by Prof. Dr. Martin Theobald and Dr. Robert C. Kahlert. Afterwards we experimented with Katya’s corpus of 80 digitised autobiographies by Australian Aboriginal authors. Our report explains how we approached the material based on what we learned during the workshop.
Methodology
We first selected 30 random pages from 6 books, with a mix between female and male authors and from six different decades. Dividing the books between the three of us, we read the first five pages of each and wrote down which different aspects we noticed that could be of interest to Katya’s research. We discussed the kind of information we all came across and decided on the most important categories, such as: person names, (family) relations, jobs, dates, places, beliefs, events, tribes, social customs, items (tools, food, religious objects, …).
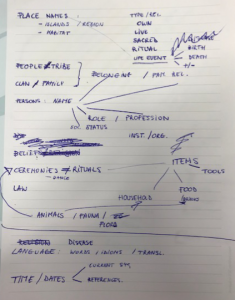 We also spent some time thinking about names for the different categories. For example how should we name the “beliefs” category: did belief denote what we wanted? Or should we instead opt for the name “religion”? In the end we chose “beliefs” as we felt that the word religion had too much of a connotation with for example Christianity or Islam. The word “beliefs” sounded more objective to us and better included the beliefs of indigenous people, as well as those of the White Europeans (i.e. Christianity). The same was true for the category “tribes”, where we eventually settled on the name “people” as it had no negative connotations and was the most clear denomination for all of us.
We also spent some time thinking about names for the different categories. For example how should we name the “beliefs” category: did belief denote what we wanted? Or should we instead opt for the name “religion”? In the end we chose “beliefs” as we felt that the word religion had too much of a connotation with for example Christianity or Islam. The word “beliefs” sounded more objective to us and better included the beliefs of indigenous people, as well as those of the White Europeans (i.e. Christianity). The same was true for the category “tribes”, where we eventually settled on the name “people” as it had no negative connotations and was the most clear denomination for all of us.
Once we defined the categories, we had to determine the most suitable format: what would go into an SQL database and which information should be included in a Wiki?
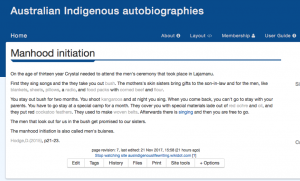
For clear, concrete categories such as names, relations, and places, we decided on a database. The beliefs, description of objects, or social rules on the other hand went into the Wiki because these categories contained unstructured data in the form of descriptions. We, for example, made a page about ceremonies which in turn contained information about specific rituals such as manhood, death, etc. An overview of what we created on the Wiki can be found here http://ausindigenouslifewriting.wikidot.com/overview. Access the page with your own login name and the password “c2dh2017”.
In the next phase we created the Entity Relationship Diagram, which meant we had to think about what constituted an entity, relation or attribute. For example, we first thought of adding the ‘People’ category in the ‘Individuals’ table, but then we noticed it would work better as a separate table. We first created the diagram on paper, and sketched our database tables to better understand the structure. Afterwards we made the digital Entity Relationship Model (ERM). To make adding information in SQL easier we also thought about which constraints and data types were included in the database. For instance:
- The name of an individual would be a varchar of 200 characters
- The social status of an individual would be restricted to a string that could consist of six options: married, divorced, widowed, de facto (common-law marriage/partnership), single or unknown.
- The information about whether a place is/was sacred or not would be encoded by an integer : 1 = yes, 0 = no and 2 = unknown.
[masterslider id=”6″]
Database Creation
 In the next phase we translated the ERM into actual database tables. We first summarised the entity tables (INDIVIDUALS, PEOPLE, PLACE, FAMILY RELATION) and the attributes they contained, including the primary key. Next, we described all the relationships tables (FAMILY, INDIVIDUAL_PLACE, PEOPLE_PLACE, BELONGING_TO) and the foreign keys (dashed lines) they contained to link entity tables. Since the database software was not installed on our machine yet, we could still decide on the exact software we wanted to use. Because we missed some essential features in the SQuirreL-software we used during the training, we decided to install MAMP for mac and use their phpMyAdmin to build our database in. We first created all tables (including mistakes), before adding constraints on some of the columns so that the manual input would be checked by the dataset itself.
In the next phase we translated the ERM into actual database tables. We first summarised the entity tables (INDIVIDUALS, PEOPLE, PLACE, FAMILY RELATION) and the attributes they contained, including the primary key. Next, we described all the relationships tables (FAMILY, INDIVIDUAL_PLACE, PEOPLE_PLACE, BELONGING_TO) and the foreign keys (dashed lines) they contained to link entity tables. Since the database software was not installed on our machine yet, we could still decide on the exact software we wanted to use. Because we missed some essential features in the SQuirreL-software we used during the training, we decided to install MAMP for mac and use their phpMyAdmin to build our database in. We first created all tables (including mistakes), before adding constraints on some of the columns so that the manual input would be checked by the dataset itself.
- Table individuals
create table individuals (
ind_id int,
ind_name varchar(200),
gender varchar(200),
age int,
role varchar(200),
soc_status varchar(200),
profession varchar(200),
primary key (ind_id)
); - Table place
create table place (
place_id int,
place_name varchar(200),
sacred_place varchar(1),
place_event varchar(200),
primary key (place_id)
); - Table people
create table people (
people_id int,
people_name varchar(200),
place_id int,
primary key (place_idpeople_id),
foreign key (place_id) references
place(place_id)
); - Table family_relations
create table family_relations (
rel_id int,
rel_type varchar(200),
primary key (rel_id)
); - Table family
create table family (
ind_id1 int,
ind_id2 int,
rel_id int,
foreign key (ind_id1) references
individuals(ind_id),
foreign key (ind_id2) references
individuals(ind_id),
foreign key (rel_id)
references family_relations(rel_id)
);
- Table ind_place
create table ind_place (
ind_id int,
place_id int,
type varchar(200),
foreign key (ind_id) references
individuals(ind_id),
foreign key (place_id) references
place(place_id)
);
- Table people_place
Note: #1215 – cannot add foreign key constraint issue
Solution: fix mistake in people
create table people_place (
people_id int,
place_id int,
foreign key (people_id)
references people(people_id),
foreign key (place_id)
references place(place_id)
);
- Table ind_place
Note: #1064 – You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘references individuals(ind_id), foreign key people_id references people(peo’ at line 4
Solution: fix mistake in people and add brackets to ind_id and people_id
create table belonging_to (
ind_id int,
people_id int,
foreign key ind_id(ind_id)
references individuals(ind_id),
foreign key people_id(people_id)
references people(people_id)
);
Some of the SQL statements were not discussed during the course, so we looked for solutions on the SQL documentation at https://www.w3schools.com/sql/. In particular, we used their code to create foreign keys, as well as the constraints and checks. The main issues during the creation of the tables were caused by a small oversight in the creation of the people_id, so once that was fixed, the other tables were created without any error statements. In the final table missing brackets caused some errors, but those were again easily resolved. In the next phase we added some restraints to certain attributes including four options for gender (male, female, other, unknown), social status (married, single, divorced, de facto, unknown, widowed), sacred place (yes, no, unknown), and family relations (parent, sibling, spouse, grandparent, parent’s sibling = aunt/uncle, sibling’s child = niece/nephew, cousin).
- gender constraint
ALTER TABLE individuals
ADD CHECK (gender in (‘M’,’F’,’X’,’-‘)) -
social status constraint
ALTER TABLE individuals
ADD CHECK (soc_status in (‘married’,’single’,’divorced’,’defacto’, ‘-‘, ‘widowed’))
- sacred place constraint
Note: 0 = no, 1 = yes, 2=unknown
ALTER TABLE place
ADD CHECK (sacred in (0,1,2));
- family relations constraint
ALTER TABLE family_relations
ADD CHECK (rel_type in (‘parent’,’sibling’,’spouse’, ‘grandparent’,’parent”s sibling’, ‘sibling”s child’, ‘cousin’))
Once we created the database model, we wanted to add data from csv files rather than input the entries one by one. In order to build the dataset collaboratively we created all tables in a google spreadsheet and added all information from the 30 pages of text we all read to our best abilities. During this exercise we noticed that some columns were missing, so I added indigenous_name to the INDIVIDUALS table, and indigenous_place_name to the PLACE table.
ALTER TABLE individuals
ADD indigenous_name varchar(200)
ALTER TABLE place ADD indigenous_place_name varchar(200)
Before we could add the data to the dataset model, we needed to export each table into a separate comma separated value file (csv) and remove the first row containing the column names. Once this was resolved, we could simply import the files automatically to the dataset. Some issues occurred whenever a key (foreign or primary) did not contain a value, so we deleted these entries. This was especially difficult for the PEOPLE table since not all people could be linked to a place and eventually we manually inserted these, given the small number of rows.
INSERT INTO people (people_id, people_name, place_id) VALUES (1,'Larumbanda',2), (2,'Balumbanda',1), (3,'Jurrgurumbanda',2), (4,'Lelumbanda',3);
This also trickled into importing all rows for PEOPLE_PLACE and BELONGING_TO. In order to share the dataset, we exported it as a SQL-file so that others can upload it to their phpMyAdmin. As a final exercise, we can now query the (limited) data we already added to try and answer some potential research questions.
Example Queries
In order to demonstrate which questions we can ask the data, we tried out two different queries . First we were interested in who belonged to which people or tribe. Therefore we needed to join the PEOPLE table to the INDIVIDUALS table based on their relation in the BELONGING_TO table. As a result we expected a list of the name of a people linked to individual names. We simply added the people id and individual id to check if the results were correct. Below we show the exact query and the resulting table.
SELECT p.people_id, p.people_name, i.ind_id, i.ind_name FROM people p INNER JOIN belonging_to b ON p.people_id = b.people_id INNER JOIN individuals i ON i.ind_id = b.ind_id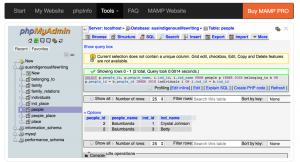
The second question we asked ourselves is who the children were in the dataset. To answer this question we needed to join several tables together, namely FAMILY, INDIVIDUALS, and FAMILY_RELATIONS where the FAMILY table provided the link to the names of both parent and child. Therefore we needed to repeat the join with the individuals table, both for the first and second individual id in the FAMILY table so that we could find information on both the parent and the child. In order to ensure we only selected children, we needed to add a where-clause stating that we only want rows where the relation id equals one. Since individuals in our list have both indigenous names and English names, we included both columns for each individual and as added information we were also interested in the gender of the children. The query and resulting table looked like this:
SELECT f.ind_id1, id1.ind_name, id1.indigenous_name, f.ind_id2, id2.ind_name, id2.indigenous_name, id2.gender FROM family f INNER JOIN individuals id1 ON f.ind_id1 = id1.ind_id INNER JOIN individuals id2 ON f.ind_id2 = id2.ind_id INNER JOIN family_relations r ON f.rel_id = r.rel_id WHERE f.rel_id = 1
Conclusion
As Morse, Singhal, and Harward (2017) note, database technologies are helping humanities scholars to find meaningful patterns in the stored data (‘distant reading’). Therefore building databases to expose relationships between entries is an important goal for a database designer when working on a digital humanities project.
Our group exercise was a useful introduction to entity relationship diagram and wiki design, as well as creating an SQL database and writing SQL queries. It also exposed the relationships hidden in the text, and inspired to learn at least the fundamentals of SQL. The ability to access and interpret data, and to translate a research question into a valid SQL query is a skill any digital humanist could only benefit from. The text from Katya’s corpus provided us with some interesting and valuable examples of what information goes into a database, the relationships we should pay attention to, and the queries we can create to answer a particular research question. For example, in Katya’s research on analysing Indigenous Australian autobiographies, she might be interested in place names and some personal attributes of individuals (e.g. belonging to a “tribe”), as those are important features characterising this particular literary genre and at the same time reflecting important historical aspects. Through close reading and entering provisional data into the dataset we noticed that some issues remained unresolved. Most problems related to missing data, and family relations can be difficult to define when people do not have a name (i.e. three sisters, my father). One possible solution would be an added field called other names (i.e. father of person x).
In addition, Katya already had a lot of books metadata organised in an Excel spreadsheet (inc. book name, author, year of publication, the Indigenous tribe the author belongs to and the location he or she lives or lived). However, she had all this information in one single table, and the workshop proved a good demonstration of how she might organise her data in a different way (e.g. using multiple interrelated tables, introducing unique identifiers for all entries, and creating a relational database).