
Thoughts on a promising relationship
Originally developed by the Adler Planetarium in Chicago in 2007 to map the stars with the help of internet users on a global scale, the crowdsourcing platform Zooniverse now hosts more than 110 peer-reviewed projects and has 1.7 million users worldwide.1 Zooniverse calls its concept “people-powered research”; its aim is to encourage collaboration between researchers and volunteers from civil society. Despite the recent trend of citizen science also in the humanities, it is not yet widely used for history projects yet.
During a one-week workshop at the Digital Humanities Oxford Summer School (22-26 July 2019), in the picturesque setting of Keble College, Samantha Blickhan, IMLS Postdoctoral Fellow & Humanities Lead for Zooniverse, gave our seminar group a sound understanding of how users can be engaged by this tool and how they can play a part in humanities research. The majority of Zooniverse projects still relate to the fields of natural sciences, astronomy and geography. The Zooniverse-team, however, is making an effort to broaden its portfolio to include humanities.
The main idea pursued by Zooniverse is to create annotations (metadata) for primarily 2D digitised objects such as photographs, drawings and texts. Initial steps have also been taken to develop the possibility of annotating audio files within a pilot project to classify urban noise pollution entitled Sounds of New York City.2 Furthermore, annotations for small video sequences are being collected by natural scientists, for example in the NestCams project, which aims to identify the breeding behaviour of different birds. Larger audio or video formats required for oral history interviews for instance are not found on the platform, however. Subject images can be up to 1000KB and any of: .jpg, .jpeg, .png, .gif, .svg, .mp3, .m4a, .mpeg, .txt, .json3
Zooniverse, an Open-Source Tool
Zooniverse is written in Python; it is open source and free of charge.4 The code and its updates are described and publicly discussed on the Zooniverse blog and are available on GitHub 5
The platform had been developed by the Adler Planetarium, Chicago, IL, USA and is funded by Google’s Global Impact Award and by a grant from the Alfred P. Sloan Foundation. The infrastructure therefore has the potential to be more sustainable than European projects in the same field such as the widely known tool Transkribus, which depends on a short-term project grant. 6
Building a History Project
There were several historians in our seminar group at DHOXSS 2019, including me. With the Public History project “Remixing the Pasts in the Digital Age: Sounds, Images, Ecologies, Practices and Materialities in Space and Time” of the C2DH in the frame of “Esch 2022 – European Capital of Culture” in mind, I started to create my own little Zooniverse project. The aim of my test-project was to classify 20th-century photographs in industrial settings in Luxembourg. Over the workshop week, I managed to draft a simple beta version of this by defining two fairly basic workflows with different tasks to identify objects, people, locations and timeframes for the uploaded pictures.
The first step involves creating one or more complete datasets for which you would like to collect annotations, and preparing a manifest-file in the form of a CSV file, including the following information:
subject_id | image_name_1 | origin | attribution | license | #secret_description
For historians this means that a crucial part of the research work has to be done beforehand: creating a complete (sub)collection and a clean manifest for upload. Copyright has to be cleared before uploading the files, since they will immediately become public – the interface platform has no function to hide your project or to take it offline from the outset. But projects are only searchable within the Zooniverse database when they have been peer-reviewed, approved by Zooniverse staff and volunteers, and released. The files are not stored on a long-term basis but only during the project phase, which may help when negotiating contracts with archives to upload digitised materials. Once a project has ended, all files are deleted from the Zooniverse server.
Since all these preparations are required beforehand, Zooniverse only intervenes at a very late stage of the collection process – yet at an early stage of the analytical process. Zooniverse allows you flexibly to add further collections during the project duration and to re-use or develop new workflows for them.
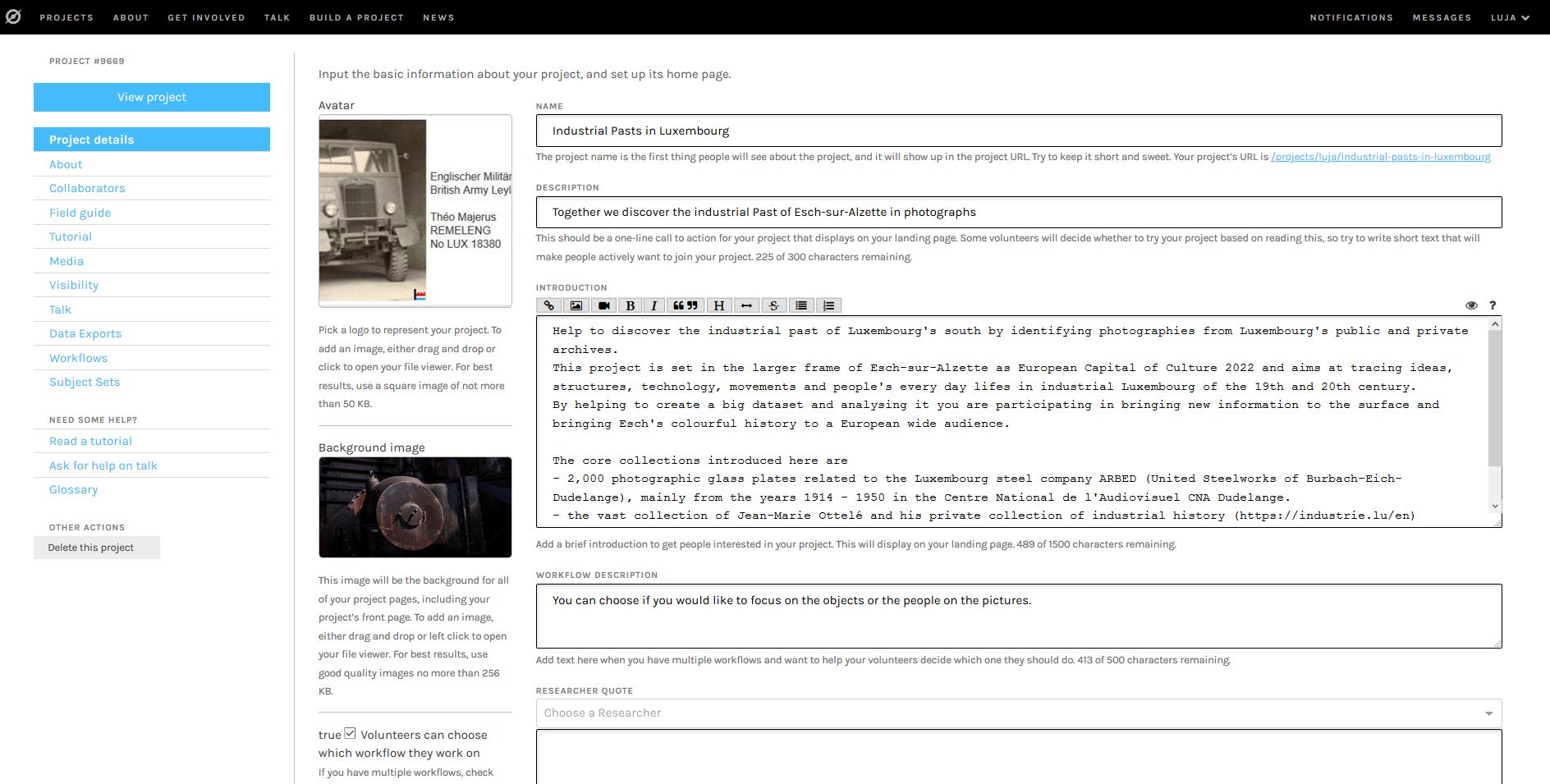
The second step is to set up your project as desktop and mobile version by following the suggested series of steps in the left column of the project builder.
The principles of good scientific practice in public history are mirrored very well by the interface design of Zooniverse, and this is one of its key selling points. Its appealing black and turquoise design, featuring
- a project title and avatar image,
- a hero image and tagline,
- workflows in tag boxes and their descriptions when scrolling down,
- visualisations of progress and participation statistics,
- a short summary abstract,
- further links
provide a clearly structured overview of the project for the user.
There is ample room for discussions in the Talk section of every project, which can be organised into various talkboards with different themes and addressees. The About section offers pages to describe the project, introduce the team and collect frequently asked questions (FAQ). It can be enhanced with the addition of further pages such as educational materials, results, etc. The interface even offers the chance to “promote” volunteers to become moderators of a talk board, for example, and to grant them more editing rights.
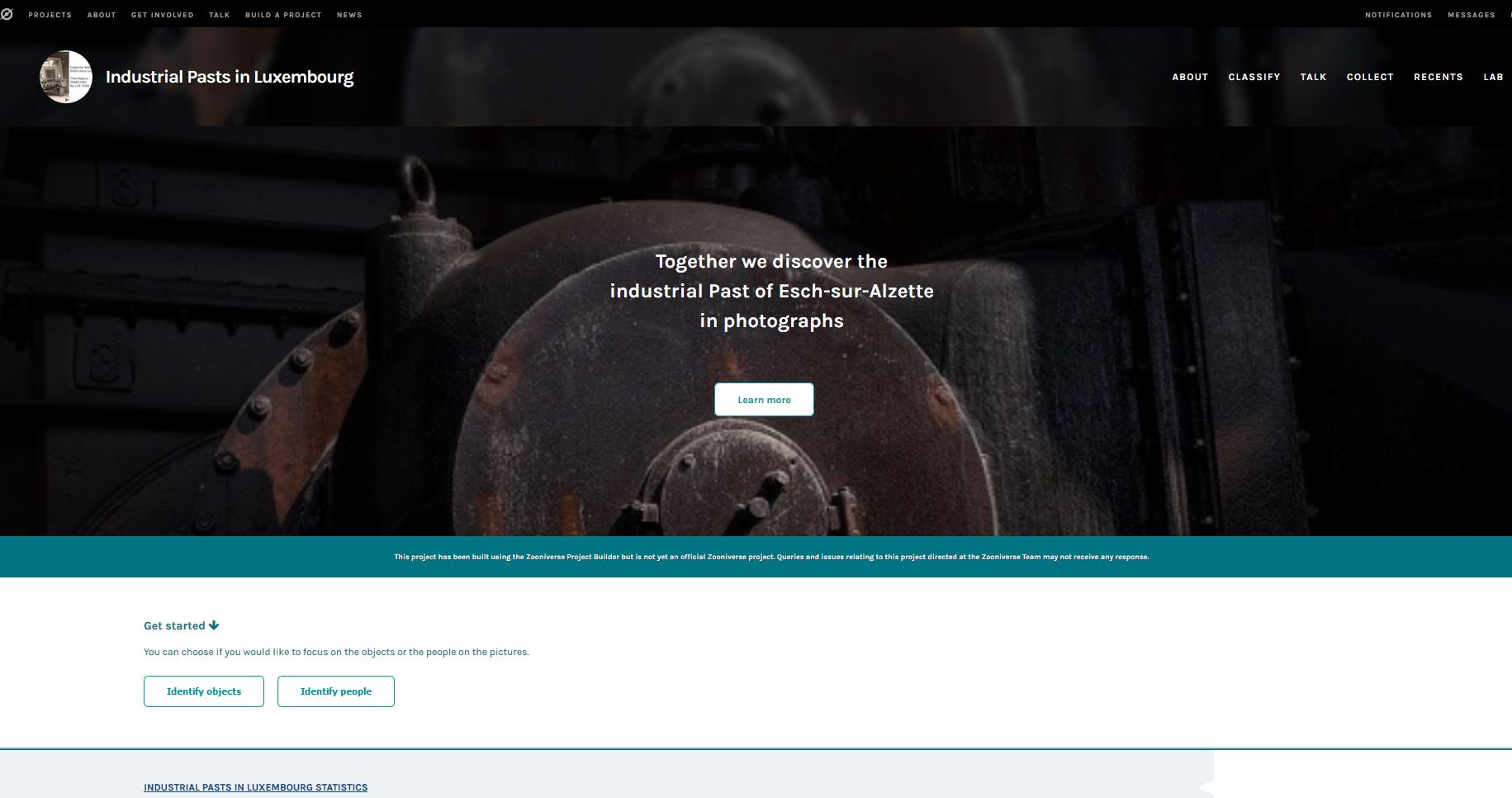
In step three the main features of the project have to be developed: defining logical workflows and feasible tasks for different target groups, writing easily understandable tutorials, and setting up interesting and productive talk boards. This took up most of the workshop time. When building the project it soon became apparent that clearly described tasks and a good tutorial are key to a successful project outcome, and producing them is a demanding challenge for the researcher.
The stable, well-designed structure of the project builder allows you to focus on developing a logical project structure and to write productive tutorials that are inclusive to the majority of platform users without having to code anything yourself.
Crowdsourced Tasks
The most frequent task in humanities projects so far was to transcribe digitised archive materials (i.e. texts).7 Zooniverse carries the potential to change this behaviour and turn Humanities research to a more public engagement away from a purely descriptive input towards more involvement in qualitative analysis, such as interpretations and critical comments.
The great advantage that became apparent when comparing the transcription tasks in Zooniverse to other transcription tools such as From the Page 8 or Scripto9 is the very flexible use of tutorials at all stages of the transcription process. You can use a parallel tutorial for each of your tasks and at the same time engage directly with users via pop-up windows when they hover over crucial areas. Every task concludes by giving volunteers the opportunity to talk about the task or the object in question, giving space for a more subjective participation than purely descriptive tasks.
The “teaching” element should not be overdone in order to allow the volunteer to focus on the actual task at hand, but a lack of interaction and stylistic explanations can cause more noise to the collection due to the lack of standards and will also cause frustration among users as they can feel unsure of whether they “did it right”. Some projects train their users so well that they can become “specialists” during the process, for example learning how to transcribe shorthand in an unpublished project on the Astrid Lindgren Code10
As well as transcriptions, other kinds of crowdsourced tasks can be designed within the project builder: Correction/modification, Categorisation, Cataloguing, Linking, Contextualisation, Content creation, Comment/response, Mapping, Geo-referencing, Translations and Annotating to train machines 11. The Zooniverse interface offers a great variant of comment fields and talk boards to overcome the objective nature of these tasks to more interpretative and critical inputs.
For the photographs from Luxembourg, I brought with me, I chose to establish two workflows: (1) to identify objects in industrial settings by applying quiz tasks and text fields, and (2) to identify people and assign professions, gender, age, etc. with a combination of quiz, text and drawing techniques. The exercises target the expertise of an envisioned Luxembourg citizen who would assess content and context of the pictures by providing text fields for entering interpretations. Due to the lack of archived material, the researchers of the projects of Remixing the Pasts in the Digital Age will be dependent on private documents collected from local participants in Luxembourg’s civil society who will also be most likely the people that will be able to give the best contextualization and interpretation of the materials to the solely nonlocal researchers. Hence, one major task of the ESCH2022 research team will also be to train the community to be able to provide those interpretation according to scientific standards.
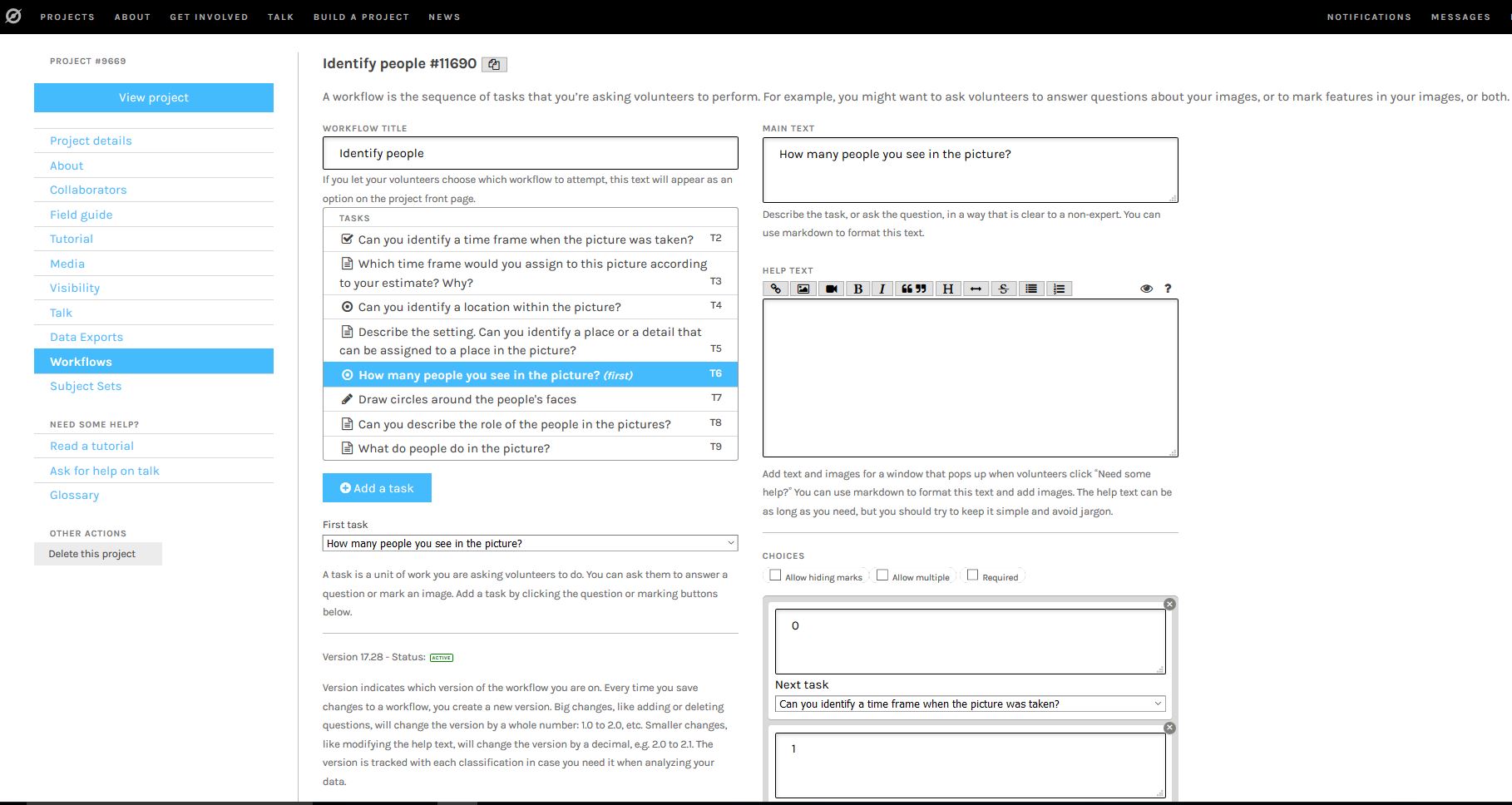
Interacting with Civil Society Volunteers
In addition to the appealing design and well-developed project builder, the expertise of the Zooniverse team in crowdsourcing and addressing the volunteering community is another big advantage of using this platform. For those who do not have the opportunity to attend a workshop like I have, there is a lot of material available online that presents the basics of long-term community engagement.12
The best practice guide of Zooniverse suggests to develop a blog accompanying the project that will enable you to give your community updates, communicate changes to workflows and tasks, give “deep dives” into examples, share community-created content, and discuss early results and next steps. The idea is to invest a minimum of one hour a week to look after your user talk boards.13
One drawback is that the interface only exists in English, and this can only be partly circumvented by writing your project details in another language or using description windows and tutorial windows for translations. At the workshop, we did not discuss with Sam how this would affect the project peer-review process. It is certainly not optimal; however, the Zooniverse team is working on extending the number of languages offered by the interface.
Exporting Project Data
We only touched on how to export project data briefly at the end of the workshop. Here again, the project builder helps you to export workflow data that was generated by the crowd in CSV format and talk data in JSON format. In GitHub you can find ready-made aggregation Python packages.
The code provides you with the highest probability of classification results. The more classifications there are for one subject, the higher the chances of receiving a “correct” result.14 For researchers, this means that the interpretation of aggregated data is still entirely up to them, a step even further would be to involve the crowd to review this data as well. Researchers are also advised to avoid an “I-don’t-know” option within the tasks. Even guesses among the volunteers are more likely to give you an accurate result.
Conclusion
How can Zooniverse change the work of historians?
The most striking observation I took away from the one-week workshop is the very high level of interaction Zooniverse can offer between researchers and volunteering crowd. Of course, you will still need to promote your project with outreach activities and find a suitable community, but by that stage it will be at a much more advanced level. At the same time, it seems that by using Zooniverse as a crowdsourcing platform you still can meet all the academic demands of your epistemic culture; the researcher is always clearly marked as the project leader who has the final say on how the project is run. The platform allows you to invest a lot of time in creating plausible workflows and tasks that will help advance your project without the need to code.
Some drawbacks I can see in the current version when considering recent trends in historiography are:
- the fact that the tool cannot be used to annotate audiovisual data that would be in high demand for oral history projects.15
- the impossibility of embedding born digital sources such as tweets16 as a data format with accompanying annotation tasks.17
However, Zooniverse does give you a chance to reevaluate the whole research process by explaining it to others, by closely developing with civil society volunteers and getting constant feedback during the data management and analysis phase.
The fact that projects are open to the public, on the other hand, may also increase pressure to engage a high number of volunteers and could distract researchers from following the project timetable efficiently. Using Zooniverse will automatically lead to a public history perspective on your project which needs to be “translated” into a more educative ductus, that may lead to reductions and simplifications in your narration. In addition, decisions such as choosing the right wording to describe complex issues may also involve pragmatic factors that would not come into play in a not public approach.
At the same time, the researcher can rely on an existing, and technically maintained platform with a high user number and an established peer-review process. Zooniverse can offer a feasible way of involving the community and provides a transparency that can lead to new forms of academic knowledge production.
Notes
- Thanks for critical feedback to Anita Lucchesi and Sytze Van Herck, thanks also to Sarah Cooper for correcting style and grammar of this post
- Mark Cartwright, Graham Dove, Ana Elisa Méndez Méndez, Juan P. Bello and Oded. Nov. 2019. Crowdsourcing Multi-label Audio Annotation Tasks with Citizen Scientists. In CHI Conference on Human Factors in Computing Systems Proceedings (CHI 2019), 4-9 May 2019, Glasgow, Scotland (UK). ACM, New York, NY, USA, 11 pages. https://doi.org/10.1145/3290605.3300522
- Information emailed by Samantha Blickhan on 5 Dec 2019.
- Coleman Krawczyk: Zooniverse Data Aggregation, Blogpost 26.10.2018, https://blog.zooniverse.org/2018/10/26/zooniverse-data-aggregation/
- https://blog.zooniverse.org/2019/11/18/panoptes-cli-1-1-now-available/
- TRANSKRIBUS (University of Innsbruck) was supported by an EU Horizon 2020 grant as part of the READ project. Funding ran out 2019 and will be continued by various partners on a smaller scale.
- Examples are The American Soldier (a collaborative project by Virginia Tech and the University of Virginia), AnnoTate (Tate Gallery, London) and Criminal Characters (University of Technology, Sydney).
- Developed by Brumfield Labs, Austin (Texas), and specialised in handwritten documents with an additional OCR function. It is not free and does not contain an elaborate search function.
- The free, open-source tool was developed by the Roy Rosenzweig Center for History and New Media, Virginia. Depending on the project, there may not be many transcription guidelines, and very few features are standardised, often resulting in low interaction with users.
- Malin Nauwerck, University of Uppsala, is the project leader.
- Talk by Samantha Blickhan at DHOXSS on 22 July 2019
- Zooniverse Best Practice Guide, Part II: In For the Long Haul
- Explained by Samantha Blickhan at DHOxSS on 25 July 2019.
- README.md https://github.com/zooniverse/aggregation
- See for example the Digital oral history inventory initiative by Douglas Lambert, C2DH
- See for example the crowdsourcing project by Anita Lucchesi #Memorecord – a memory harvest
- As for Anita Lucchesi’s choice to use Twitter as an interface, she explains that it offered an already existing community and constitutes an already familiar interface to them.